











前置き
今回は、Google ColabとOpenAIのAPIを活用し、RAG(検索拡張生成)の仕組みを使って、Google ドライブ上の資料を参照しながら回答できるQAシステムのプロトタイプを作成してみます。
(具体的な用途例として社内文書を対象としたQAシステムのプロトタイプを想定してみました)
実行環境にGoogle Colabを使用しました
Colabはブラウザ上でPythonを手軽に実行でき、必要なツールもあらかじめ揃っているため、開発や検証がスムーズに行えます。
また、回答に利用する資料は Google ドライブに保存されたPDFやPowerPoint、テキスト、CSVファイルを対象とすることで、すでに管理されているドキュメントをそのまま活用できます。
Google Colabはあくまでプロトタイプ用途
Google Colabは、あくまでプロトタイプや検証用途での実行環境として利用することが前提です。理由は以下の通り。
①セキュリティやデータ管理の制限
Colabはクラウド上で動作するため社内の機密資料や個人情報を扱うには適していません。
認証やアクセス制御も限定的で、企業利用の観点ではリスクがあります。
②実行環境が一時的
セッションが切れるとデータが消えるため、永続的な運用や自動化には不向きです。
実運用には別途、オンプレミス環境や専用サーバーへの移行、API化やUI実装などが必要になります。
RAGとファインチューニング(学習)の違い
今回のようなQAシステムでは、「文書をAIに学習させる」という表現をしてしまいがちですが、これは正確ではありません。
外部の文書を検索・参照して回答を生成する仕組みです。モデルは文書の内容を学習しているのではなく、都度調べて答えてるだけ。
モデルの中に知識を埋め込む手法で、反映には多くのデータ・時間・コストがかかり、更新も手間です。また、実施にはGPTなどのベースモデルから派生させた独自モデルを構築・管理する必要があり、技術的なハードルも高くなります。
今回のケースでは、GPTモデルにRAGを組み合わせることで、「文書を調べながら回答する」形となります。GPT自身が知識を持っているわけではなく、毎回必要な情報を参照して回答を出すというイメージです。
事前準備
OpenAIのAPIを使うにはトークンキー(APIキー)が必要になります。トークンは利用に応じて課金されるため、事前にOpenAIアカウントへクレジット(残高)をチャージしておく必要があります。
また、ChatGPT Plusに加入していても、APIの利用は別の課金体系になっており、別途チャージが必要となります。
このまま読み進める場合は、アカウントを作ってチャージをしておきましょう。
※必要最低限の金額、かつ、オートチャージもされない設定で進めていきます。
OpenAI API課金方法
OpenAIのアカウントを持ってない方はアカウントを作成しておきましょう。
その後、OpenAIのユーザページにアクセスします。

左メニューの「Billing」を選択して、「Add to credit balance」を選択します。
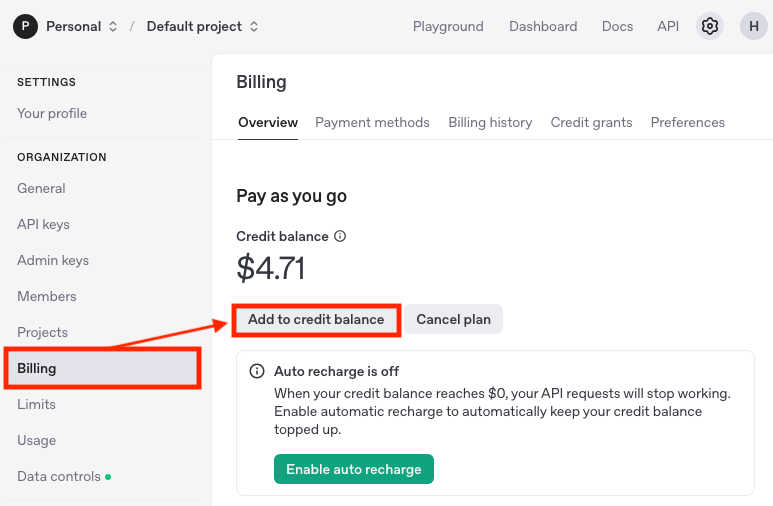
キャプチャはあらかじめ課金がしてある状態ですので表示に差異があるかもしれません。
(新規で課金する場合は「Add payment details」とかになってるかも)
クレジットカード情報を登録すると、Configure Paymentという画面がでてくるので、「Initial credit purchase」に金額を入れます。
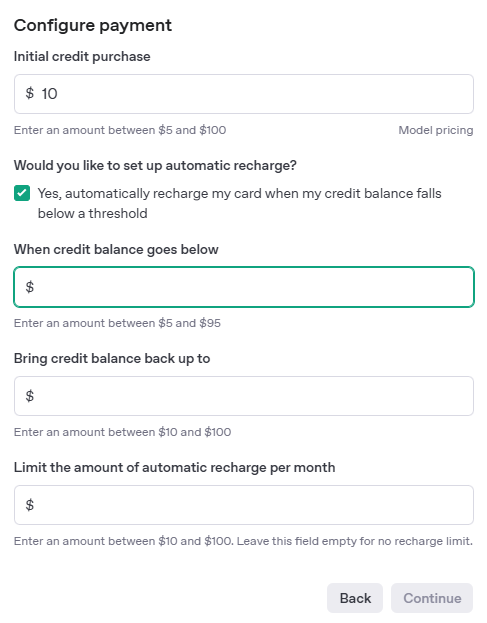
最低金額は$5から設定できます。また、使用期限もあるみたいなので、初めは必要最低限でよいと思います。
あと、自分はオートチャージされたくないので「Would you like to set up automatic recharge?」のチェックを外しました。
最後に「Continue」すればチャージはオッケー。
OpenAI APIトークン発行方法
OpenAIのユーザページにアクセスします。
左メニューの「API keys」を選択して、「+ Create new secret key」を選択します。
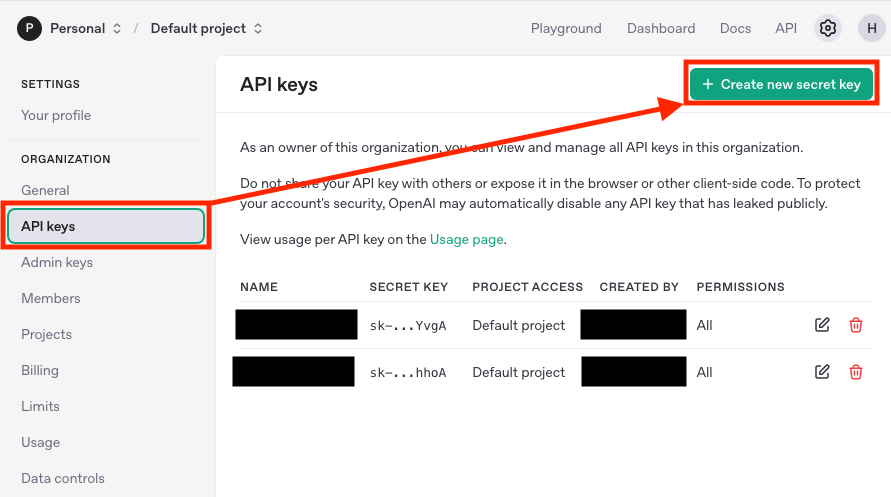
「Name」に任意の名称を指定して、「Project」のプルダウンは「Default project」にしてCreate secret keyを選択します。
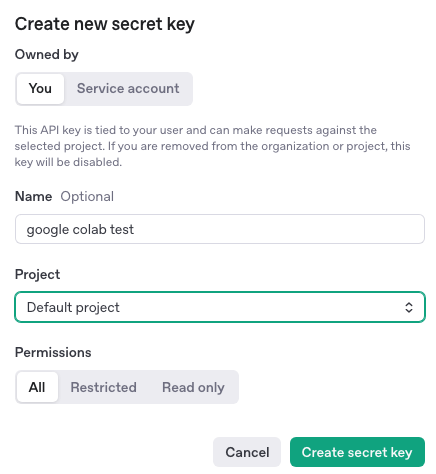
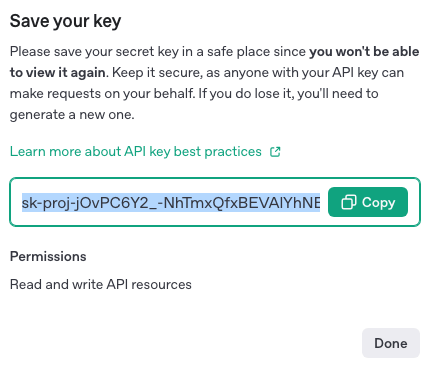
そうすると以下のようなモーダルが立ち上がるので発行されたキーをCopyしてどこか忘れない場所に控えておきます。
後で参照できなくなるのでここで忘れずにひかえておきます。
Google ドライブに読み込ませる資料をアップしておく
マイドライブに「マイドキュメント」というフォルダを作成して、その中に「社内ガイドサンプル1.pdf」「社内ガイドサンプル2.txt」というPDFとテキストのサンプルファイルをおきました。
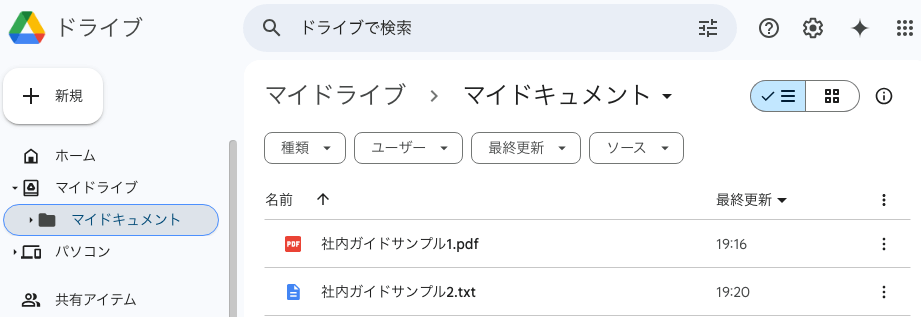
パワポとか、エクセルとか、スプレットシートも読み込ませて解析できるようですが、今回は一旦この2つの拡張子のファイルをそれぞれ読み込ませる形でやっていこうとおもいます。
準備は以上!
本題
ここからやっとシステムの構築です!
Google Colabにアクセス
Google Colabにアクセスします。

New Notebookを選択します。
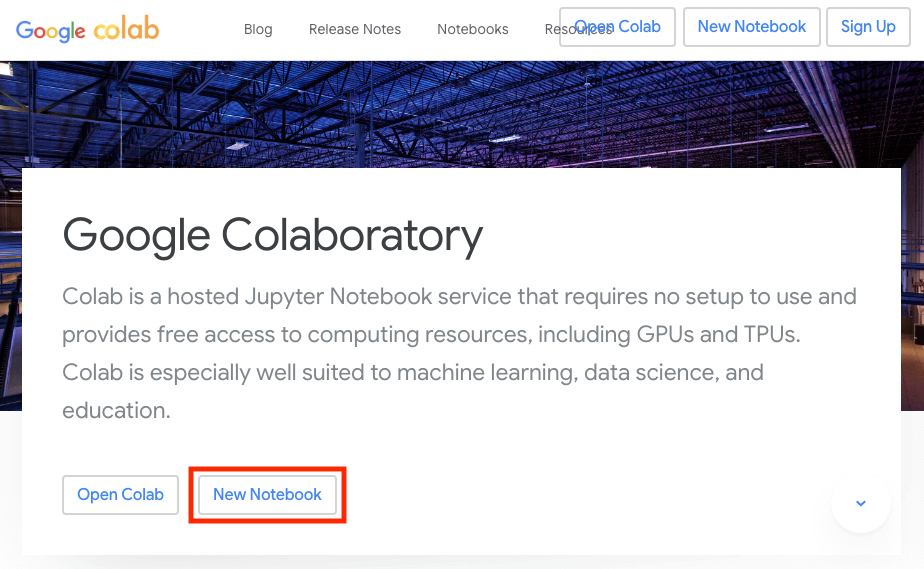
めっちゃ大雑把な使い方の説明としては、赤枠箇所にパイソンコードを入力して、左にある再生ボタンを押下することでコードが実行されます。
上部の青枠箇所の「+ コード」を押下して新しい行を追加できます。
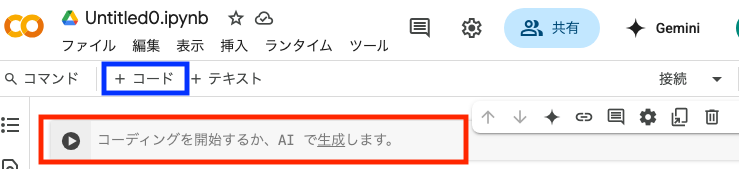
試しながら進めていきましょう!
Pythonコードの実行
以下のコードを順に実行していきます。
※コードは部分的にまとめて実行することも可能ですが、理解を深めるためにポイントごとに区切って実行しています。
1. ライブラリのインストール
!pip install openai==0.28 langchain==0.0.310 chromadb==0.4.15 tiktoken==0.5.1 pypdf==3.17.4上記実行して、ライブラリのインストールが終わると「セッションを再起動する」が表示されますが、こちらは再起動を選択しておきます。
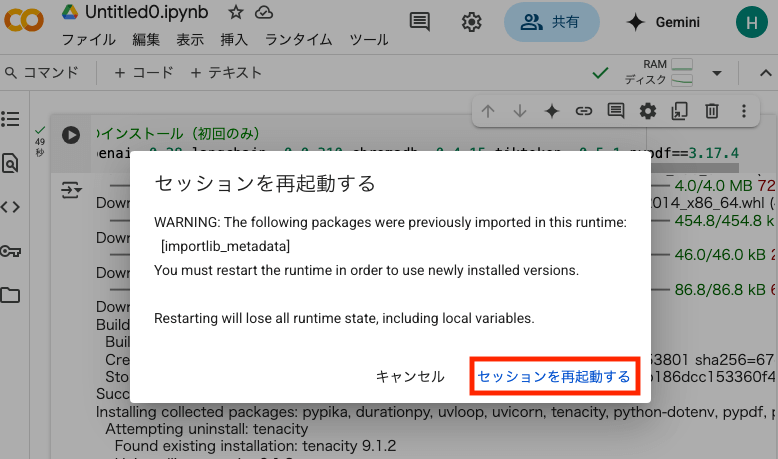
以降、「+ コード」を押下して新しい行を追加してコードを入力 => 実行しながら進めていきます。
2.Google Drive をマウント
from google.colab import drive
drive.mount('/content/drive')上記実行すると、Googleドライブへのアクセス許可について問われます。
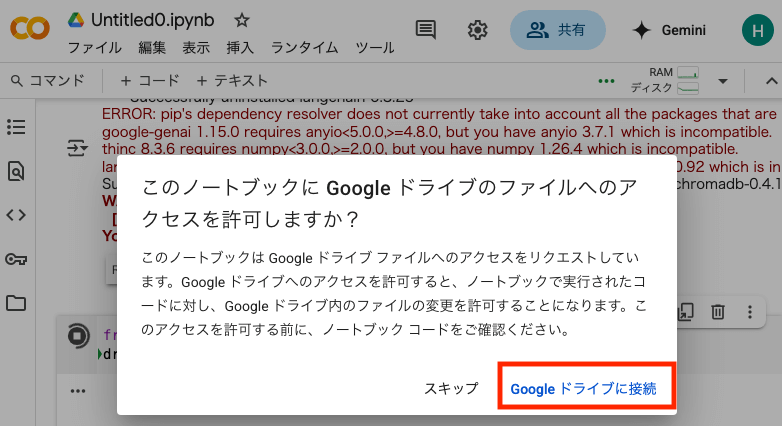
このサンプルでは「すべて選択」で進めてしまってます。
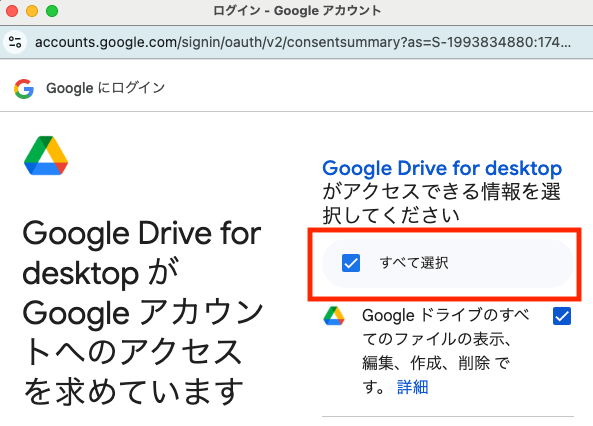
処理が終わるとドライブがマウントされます。

3.モジュールのインポート
import os
import glob
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI4.OpenAI APIキーを設定
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"あらかじめ発行したキーに差し替えて実行します。
5.対象フォルダとファイルの読み込み
# Google Drive内の対象フォルダの指定
folder_path = "/content/drive/MyDrive/マイドキュメント"
# 対象フォルダ内のファイルの読み込み(PDFとTXT)
documents = []
for path in glob.glob(folder_path + "/*.pdf") + glob.glob(folder_path + "/*.txt"):
if path.endswith(".pdf"):
documents.extend(PyPDFLoader(path).load())
elif path.endswith(".txt"):
documents.extend(TextLoader(path, encoding="utf-8").load())6.文書をチャンクに分けて(テキスト分割)ベクトル化
# テキスト分割
texts = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100).split_documents(documents)
# ベクトルDBの作成とQA構築
vectordb = Chroma.from_documents(texts, OpenAIEmbeddings())●コード補足
読み込んだ文書がそのままではAIは理解しにくい。
・そのためまず「読みやすいサイズ(例:1000文字)」に分割(=チャンク化)
・それぞれのチャンクをAIが扱える形(=ベクトル)に変換する
こうすることで、質問に関連する部分を検索で取り出せるようになる
以下は好みで適宜値で調整します。
chunk_size=1000
→ 1つのチャンク(分割されたテキスト)の最大文字数。
例:1000文字ずつに分けて処理します。
chunk_overlap=100
→ チャンク同士を100文字ぶん重ねて分割します。
文のつながりが途切れないようにするためです。
7.LLMの指定とQAチェーン構築
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model_name="gpt-4-turbo"),
retriever=vectordb.as_retriever()
)「model_name=”gpt-4-turbo”」の部分で利用するモデルの指定ができます。以下は参考。
| モデル名 | 特徴 | トークン単価(入力 / 出力) | 用途例 |
|---|---|---|---|
gpt-3.5-turbo | 軽量・安価・高速 | 安い(約 $0.0015 / $0.0020) | 動作検証、応答スピード重視の場面 |
gpt-4-turbo | 高精度・長文対応 | 高い(約 $0.01 / $0.03) | 文章生成、精度が重要な場面 |
8.質問してみる
result = qa.run("このフォルダに含まれる資料の要点を教えてください")
print("【回答】", result)上記実行するとドライブ上にあるファイルを解析して以下のように回答してくれます!
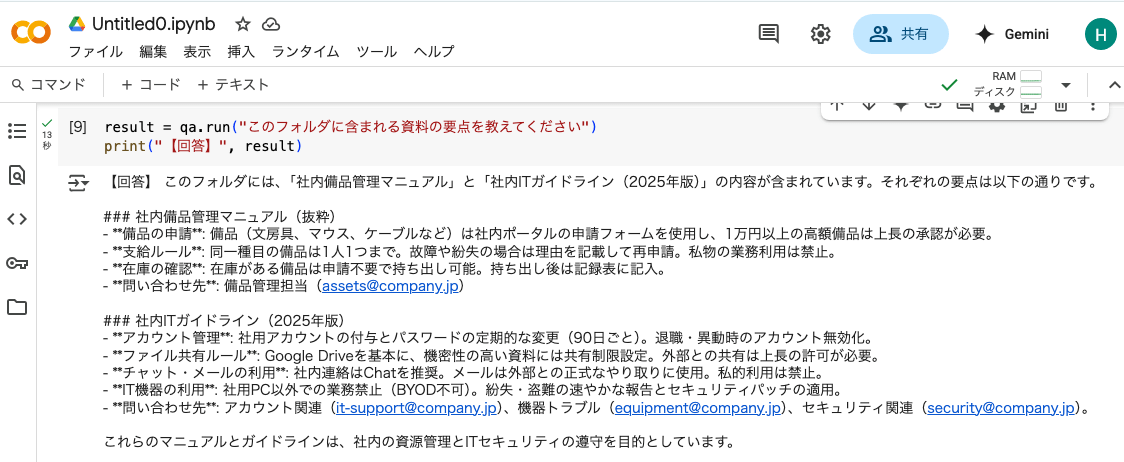
これはすごい!シンプルに感動!
まとめ
冒頭でも述べた通り、Google Colab は本番運用には適していませんが、今回の内容はRAGによるQAシステムのプロトタイプとしては十分に機能する構成になっています。
実際に、手元のPDFやテキストファイルを対象にGPTが「調べて答える」仕組みを手軽に試すことができ、実用的な基盤をイメージするには最適なステップです。
今後、より、プロトタイプとして肉付けしていきたい場合は、Flaskなどで簡易Webアプリを構築して、ngrokで外部アクセスできるようにして、ブラウザから質問できる形式に拡張することもできるでしょう(このあたりは、今後ゆっくり試していきたいと思います)。
↓拡張版もつくりました。

小さなプロトタイプから始めて、少しずつ現実的な仕組みに発展させていけるのがRAGの魅力でもあります。

