












前回は、Google Colab上でRAGを使い、ファイルを読み込ませてQAシステムのプロトタイプを作りました。

今回はその拡張版です。
前置き
成果物
Google ColabとOpenAI APIを活用し、Googleドライブ上の資料を参照して回答できるRAG型QAシステムのプロトタイプを構築します。さらに、ブラウザ上にチャットUIを実装し、Colabと連携して対話できるWebアプリとして動作させます。
構成
システム構成図は以下のようなイメージ
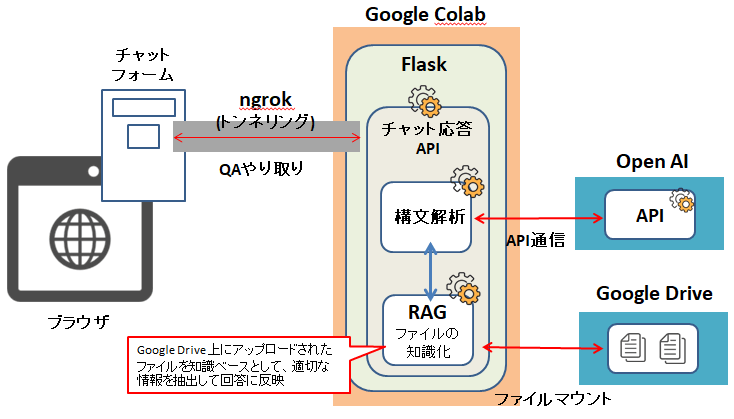
事前準備
以下の事前準備が必要になります。
OpenAI APIへの課金 + トークンの発行
課金を済ませて、トークンを発行しておきます。
ちなみに、ChatGPT Plusに加入していても、APIの利用は別の課金体系になっており、別途チャージが必要となります。
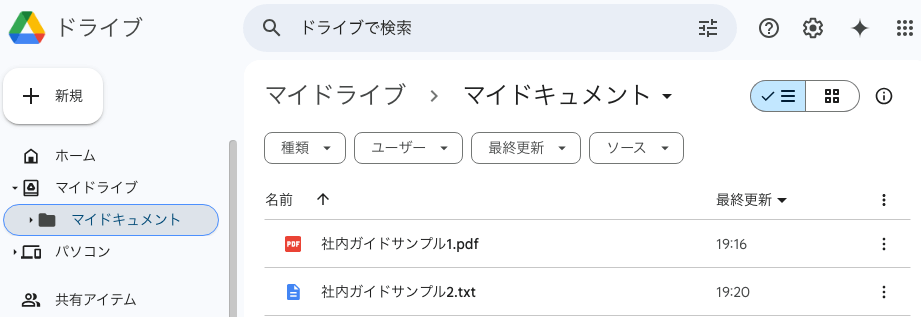
Google ドライブに読み込ませる資料をアップしておく
マイドライブに「マイドキュメント」というフォルダを作成して、その中に「社内ガイドサンプル1.pdf」「社内ガイドサンプル2.txt」というPDFとテキストのサンプルファイルをおきました。
上記までの準備に関しては前回の記事に詳細記載してありますので、ここではあっさり目に書いておきます。
ngrokのアクセストークンの発行
ngrokは、ローカル環境(ここでは Google Colab 上の Flask アプリ)を、ブラウザ(チャットフォーム)からアクセスできるようにするトンネルサービスです。

アカウントを持ってない場合は右上の「Sign up」でアカウントの発行を。
ログインする場合は「Log in」しておきます。
ログインしたら左メニューに「Your Authtoken」をひらけばトークンをコピーできる状態になります。
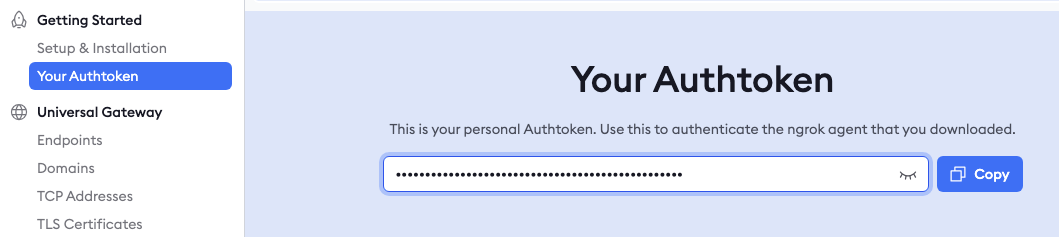
後ほど必要になるので、どこかに控えておくか、必要なときにコピーできればOKです!
本題
Google Corabをひらく
Google ColabのNotebookをひらいておきます。

Googleドライブのファイルから回答を生成するRAG 環境を構築する
以下のコードをGoogle ColabのNotebook上で順に実行していきます。
コードは部分的にまとめて実行することも可能ですが、理解を深めるためにポイントごとに区切って実行しています。
必要なライブラリを一括インストールする
!pip install openai==0.28 langchain==0.0.310 chromadb==0.4.15 tiktoken==0.5.1 pypdf==3.17.4Google ドライブをマウントしてファイルにアクセスする
from google.colab import drive
drive.mount('/content/drive')必要なモジュールのインポート
# ファイル操作
import os, glob
# RAG関連
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAIOpenAIのAPIキーの設定
# 環境変数にAPIキーを設定
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"Googleドライブ上のファイルを読み込み、テキストを分割・ベクトル化する
# Googleドライブ上のファイル読み込み
folder_path = "/content/drive/MyDrive/マイドキュメント"
documents = []
for path in glob.glob(folder_path + "/*.pdf") + glob.glob(folder_path + "/*.txt"):
if path.endswith(".pdf"):
documents.extend(PyPDFLoader(path).load())
elif path.endswith(".txt"):
documents.extend(TextLoader(path, encoding="utf-8").load())
# テキスト分割
texts = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100).split_documents(documents)
# ベクトルDBの作成とQA構築
vectordb = Chroma.from_documents(texts, OpenAIEmbeddings())補足:マウントした Googleドライブ上のフォルダから、PDF やテキストファイルを自動で読み込み、LangChain の Loader で内容を抽出します。
文書を一定の長さで分割したうえで、OpenAI の埋め込みモデルを使ってベクトルデータに変換し、検索可能なデータベース(Chroma)を構築します。
質問応答システムの構築
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model_name="gpt-4-turbo"),
retriever=vectordb.as_retriever()
)補足:ベクトルデータベースを検索して、その結果をもとにGPTモデルで回答を生成します。
model_name=”gpt-4-turbo” の部分は、必要に応じて他のモデル名(例:gpt-3.5-turbo)に変更することも可能です。
チャット応答APIの実装
次は、Google Colab上でPythonのFlaskを使って、簡単なチャット応答API(Webアプリ)を作成します。
※続けてコードを実行していきます。
ライブラリのインストール
!pip install flask pyngrok flask-corsngrokトークンを設定
from pyngrok import ngrok, conf
conf.get_default().auth_token = "ngrokトークンを貼り付け"トンネリングされるURLを表示
public_url = ngrok.connect(5000)
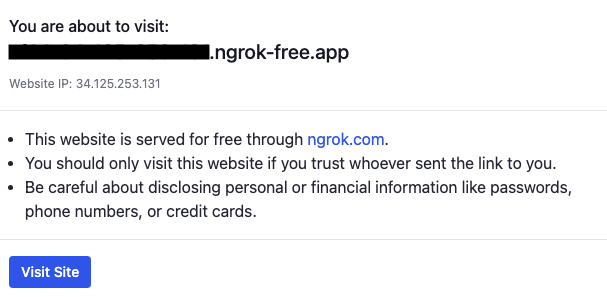
print(public_url)上記実行するとリンクが表示されるので赤枠箇所を控えておきます。

リンクにアクセスして以下のような画面になっていればOKです。
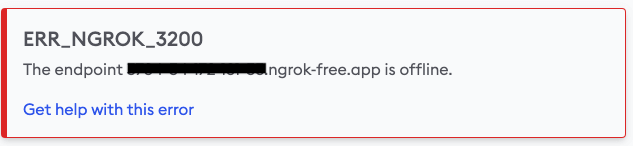
一定時間経過するとリンクが無効になるので、以下のような画面になっていた場合、再度トンネルリンクを発行する必要があります。
チャット用APIエンドポイントの実装
from flask import Flask, request, jsonify
from flask_cors import CORS
import threading
app = Flask(__name__)
CORS(app)
@app.route("/chat", methods=["POST"])
def chat():
user_input = request.json.get("message", "")
reply = qa.run(user_input)
return jsonify({"reply": reply})
def run():
app.run(port=5000)
threading.Thread(target=run).start()補足:PythonのFlaskを使って簡単なチャットAPIを作成し、それをngrok経由で外部公開しています。このまま待機状態にしておきます。
チャットボットUIになるHTMLを実装
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Colabチャットボット</title>
</head>
<body>
<h2>Colab連携チャットボット</h2>
<div>
<input type="text" id="userInput" placeholder="メッセージを入力">
<button onclick="sendMessage()">送信</button>
</div>
<div id="chatLog" style="margin-top:20px;"></div>
<script>
async function sendMessage() {
const message = document.getElementById("userInput").value;
// トンネリングURLを貼り付ける
const response = await fetch("https://XXXX-XX-XX-XXX-XX.ngrok-free.app/chat", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({ message: message })
});
const data = await response.json();
const chatLog = document.getElementById("chatLog");
chatLog.innerHTML += `<p><strong>あなた:</strong>${message}</p>`;
chatLog.innerHTML += `<p><strong>Bot:</strong>${data.reply}</p>`;
document.getElementById("userInput").value = "";
}
</script>
</body>
</html>以下箇所にトンネリングURLを貼り付けます。※「/chat」の部分は残るようにしてください。
// トンネリングURLを貼り付ける
const response = await fetch("https://XXXX-XX-XX-XXX-XX.ngrok-free.app/chat", {このファイルを.html拡張子で保存します(ファイル名は任意)
使ってみる
保存したhtmlファイルをブラウザでアクセスしましょう。
Google ドライブ上にあるファイルの内容に関する質問を入力してみてください。
正しく連携できていれば、以下のようにファイルの内容をもとにした回答が返ってくるはずです!

補足
大雑把な質問をすると、「その具体的な要点を教えてください」といったような、曖昧な回答が返ってくることがあります。
そんなときは、もう少し具体的な表現に言い換えてみると、より的確な返答が得られるはずです。
解答の精度や柔軟な応答制御を高めるには、プロンプトエンジニアリングを工夫する必要がありそうですが、今回はプロトタイプということで、一旦ここまでで区切りたいと思います。
なお、前回の記事でもお伝えした通り、Google Colabやngrok のセッションは一時的なものです。
本番運用には適しませんが、この仕組みの構成自体は本番環境にも応用可能です。プロトタイプのステップとしては十分な内容と言えるでしょう。
